Track notebooks & scripts¶
This guide explains how to use track() & finish() to track notebook & scripts along with their inputs and outputs.
For tracking pipelines, see: Pipelines – workflow managers.
# !pip install 'lamindb[jupyter]'
!lamin init --storage ./test-track
Show code cell output
→ initialized lamindb: testuser1/test-track
Track a notebook or script¶
Call track() to register your notebook or script as a transform and start tracking inputs & outputs of a run.
import lamindb as ln
ln.track() # initiate a tracked notebook/script run
# your code
ln.finish() # mark run as finished, save execution report, source code & environment
Here is how a notebook with run report looks on the hub.
Explore it here.

Assign a uid to a notebook or script
If you want to retain one version history when renaming notebooks and scripts, pass a uid to ln.track(), e.g.
ln.track("9priar0hoE5u0000")
To obtain a uid value, copy it from the logging statement (Transform('9priar0hoE5u0000')) when running ln.track() a first time without passing a uid.
Load a notebook or script¶
On the hub, search or filter the transform page and then load a script or notebook on the CLI. For example,
lamin load https://lamin.ai/laminlabs/lamindata/transform/13VINnFk89PE
Query a notebook or script¶
You find your notebooks and scripts in the Transform registry (along with pipelines & functions). Run stores executions.
You can use all usual ways of querying to obtain one or multiple transform records, e.g.:
transform = ln.Transform.get(key="my_analyses/my_notebook.ipynb")
transform.source_code # source code
transform.latest_run.report # report of latest run
transform.latest_run.environment # environment of latest run
transform.runs # all runs
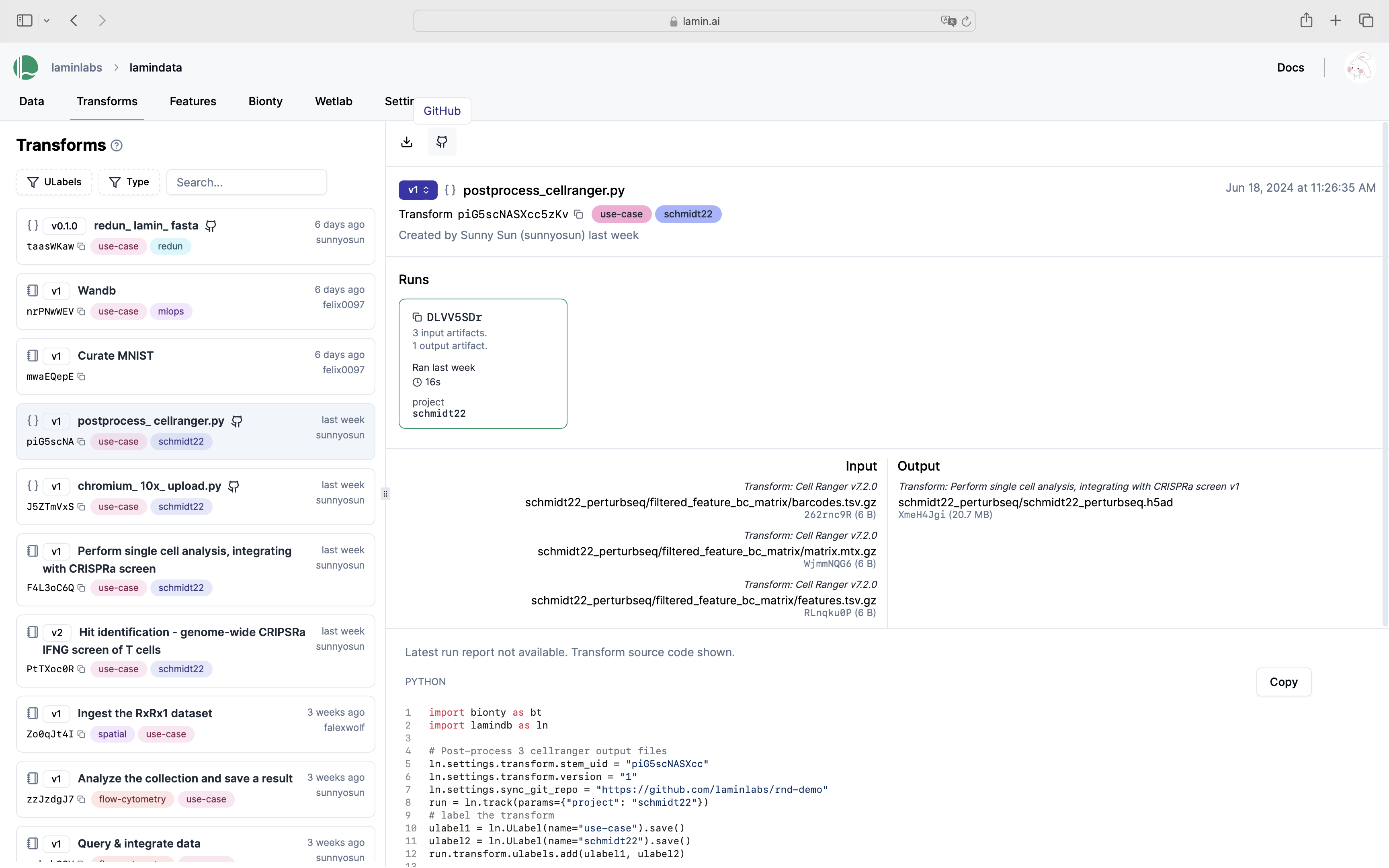
Sync scripts with git¶
To sync with your git commit, add the following line to your script:
ln.settings.sync_git_repo = <YOUR-GIT-REPO-URL>
import lamindb as ln
ln.settings.sync_git_repo = "https://github.com/..."
ln.track()
# your code
ln.finish()
You’ll now see the GitHub emoji clickable on the hub.
Track parameters¶
In addition to tracking source code, run reports & environments, you can easily track run parameters.
Track run parameters¶
Before tracking parameter values, you need to define valid parameters, e.g.:
import lamindb as ln
ln.Param(name="input_dir", dtype="str").save()
ln.Param(name="learning_rate", dtype="float").save()
ln.Param(name="preprocess_params", dtype="dict").save()
Show code cell output
→ connected lamindb: testuser1/test-track
Param(name='preprocess_params', dtype='dict', created_by_id=1, space_id=1, created_at=2025-01-12 14:02:28 UTC)
Upon running the below script without those parameters defined, you’ll get a ValidationError from which you can copy & paste the definitions.
import argparse
import lamindb as ln
if __name__ == "__main__":
p = argparse.ArgumentParser()
p.add_argument("--input-dir", type=str)
p.add_argument("--downsample", action="store_true")
p.add_argument("--learning-rate", type=float)
args = p.parse_args()
params = {
"input_dir": args.input_dir,
"learning_rate": args.learning_rate,
"preprocess_params": {
"downsample": args.downsample, # nested parameter names & values in dictionaries are not validated
"normalization": "the_good_one",
},
}
ln.track(params=params)
# your code
ln.finish()
Run the script.
!python scripts/run-track-with-params.py --input-dir ./mydataset --learning-rate 0.01 --downsample
Show code cell output
→ connected lamindb: testuser1/test-track
→ created Transform('PQ8b2NuRiOiz0000'), started new Run('caQFc6b7...') at 2025-01-12 14:02:32 UTC
→ params: input_dir=./mydataset, learning_rate=0.01, preprocess_params={'downsample': True, 'normalization': 'the_good_one'}
→ finished Run('caQFc6b7') after 0d 0h 0m 1s at 2025-01-12 14:02:33 UTC
Query by run parameters¶
Query for all runs that match a certain parameters:
ln.Run.params.filter(
learning_rate=0.01, input_dir="./mydataset", preprocess_params__downsample=True
).df()
Show code cell output
| uid | name | started_at | finished_at | reference | reference_type | _is_consecutive | _status_code | space_id | transform_id | report_id | _logfile_id | environment_id | initiated_by_run_id | created_at | created_by_id | aux | _branch_code | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 1 | caQFc6b72ztb1CQko3Fv | None | 2025-01-12 14:02:32.011754+00:00 | 2025-01-12 14:02:33.586941+00:00 | None | None | None | 0 | 1 | 1 | 2 | None | 1 | None | 2025-01-12 14:02:32.011809+00:00 | 1 | None | 1 |
Note that:
preprocess_params__downsample=Truetraverses the dictionarypreprocess_paramsto find the key"downsample"and match it toTruenested keys like
"downsample"in a dictionary do not appear inParamand hence, do not get validated
Access parameters of a run¶
Below is how you get the parameter values that were used for a given run.
run = ln.Run.params.filter(learning_rate=0.01).order_by("-started_at").first()
run.params.get_values()
Show code cell output
{'input_dir': './mydataset',
'learning_rate': 0.01,
'preprocess_params': {'downsample': True, 'normalization': 'the_good_one'}}
Here is how it looks on the hub.
Explore all parameter values¶
If you want to query all parameter values across all runs, use ParamValue.
ln.core.ParamValue.df(include=["param__name", "created_by__handle"])
Show code cell output
| value | hash | space_id | param__name | created_by__handle | |
|---|---|---|---|---|---|
| id | |||||
| 1 | ./mydataset | None | 1 | input_dir | testuser1 |
| 2 | 0.01 | None | 1 | learning_rate | testuser1 |
| 3 | {'downsample': True, 'normalization': 'the_goo... | None | 1 | preprocess_params | testuser1 |
Manage notebook templates¶
A notebook acts like a template upon using lamin load to load it. Consider you run:
lamin load https://lamin.ai/account/instance/transform/Akd7gx7Y9oVO0000
Upon running the returned notebook, you’ll automatically create a new version and be able to browse it via the version dropdown on the UI.
Additionally, you can:
label using
ULabel, e.g.,transform.ulabels.add(template_label)tag with an indicative
versionstring, e.g.,transform.version = "T1"; transform.save()
Saving a notebook as an artifact
Sometimes you might want to save a notebook as an artifact. This is how you can do it:
lamin save template1.ipynb --key templates/template1.ipynb --description "Template for analysis type 1" --registry artifact
Show code cell content
assert run.params.get_values() == {
"input_dir": "./mydataset",
"learning_rate": 0.01,
"preprocess_params": {"downsample": True, "normalization": "the_good_one"},
}
# clean up test instance
!rm -r ./test-track
!lamin delete --force test-track
• deleting instance testuser1/test-track